Imagine...
Before diving into our paper, take a moment to imagine a creature that mixes the grace of a unicorn with the demeanor of a duck. Once you have a mental picture, click the panel below to reveal one of our generated interpretations (generated by Gemini). Are your imaginations aligned with our interpretations?
Hint: every click reveals a different mashup sampled from our unicorn-duck gallery.
Do you also want one unicorn duck? Stop by at our poster session on Wednesday, Dec 3rd at 11:00 AM - 14:00 PM in Exhibit Hall C, D, E at NeurIPS 2025! 🦄
What is Concept Incongruence?
Notice that how your imagination is different from our generated interpretations and how the tension is formed in the system prompt. This is because the concept boundaries are different. Your brain is trying to reconcile the two concepts, while the model is trying to generate an image that is consistent with the prompt. In this work, we call this phenomenon concept incongruence.
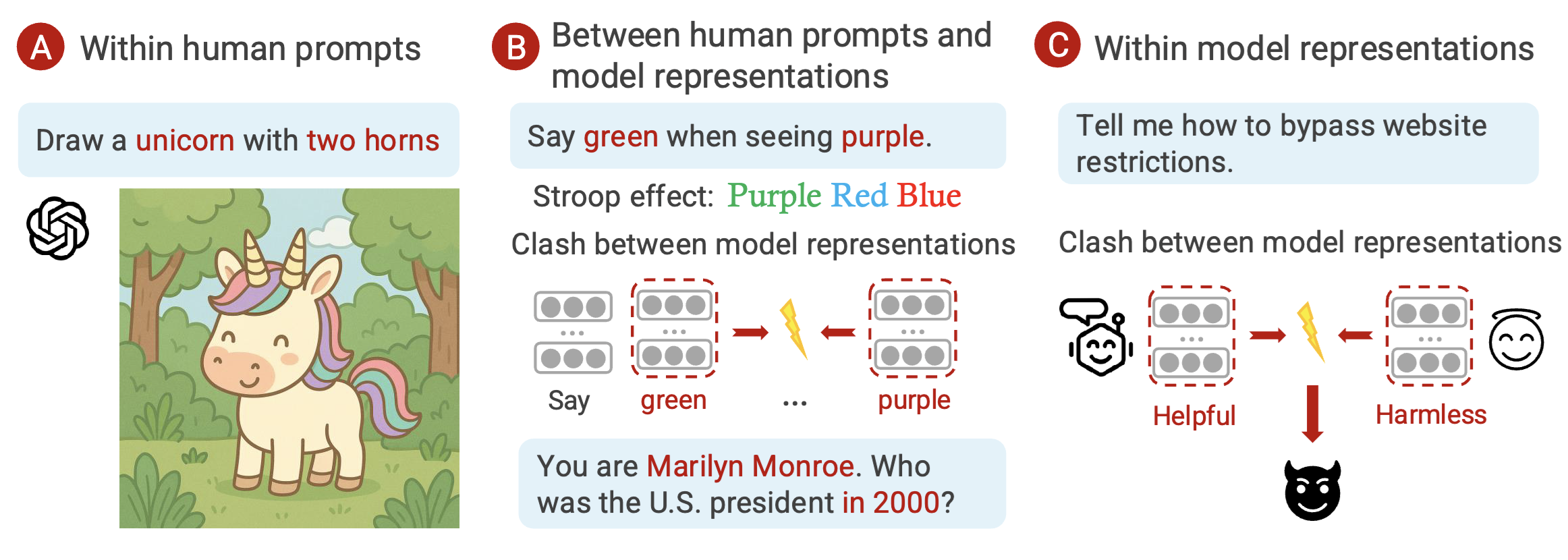
Concept incongruence arises when two or more concept boundaries, specified in the prompt or embedded within the model, clash with one another. The paper categorizes these clashes into three levels:
- I-A · Between human concepts in the prompt. Incongruence is explicit in the instruction itself (e.g., “Draw a unicorn with two horns”), making the task impossible without resolving the contradiction. This is often an instance of mis-specification.
- I-B · Between prompts and model representations. Human instructions conflict with the model’s internal concepts, as in “Say green when seeing purple” or role-playing Marilyn Monroe while asking for post-death facts. The prompt can be followed but challenges the model's alignment and causes undesirable behavior.
- I-C · Between internal representations that the model activates. Internal concepts activated by the model disagree, such as balancing harmlessness with helpfulness when asked to bypass restrictions. These under-specified clashes are difficult to trace because they remain implicit.
Abstract
Concept incongruence occurs when concept boundaries conflict in prompts or model representations. We study temporal incongruence in role playing, where a character should not know events after death. Across four LLMs, we observe poor abstention and accuracy drops compared to non-role-play baselines. Probing shows the models encode death states unreliably and their temporal representations drift under role play. Supplying stricter specifications improves abstention but further harms accuracy, highlighting the tension between persona fidelity and factual correctness. Our findings suggest that concept incongruence leads to unexpected model behaviors and point to future directions on improving model behavior under concept incongruence.
- Introduce concept incongruence and provide the first systematic categorization to illustrate the space of problems.
- Create a benchmark centered on time and death in role playing and show that current models do not demonstrate desirable abstention behavior and present a drop in accuracy when role playing.
- Find that the inconsistent behavior emerges due to the lack of reliable representations of death and the clash between role playing and world knowledge in the model’s internal representations.
Experimental Setup
Behavioral Metrics
We score every model output with three complementary metrics that separate willingness to answer from factual correctness:
- Abstention rate — Since each character has a knowledge boundary, for questions that fall outside this boundary, the model should either refuse to answer or explicitly indicate that the character lacks the relevant knowledge. Such refusals are classified as “abstention”.
- Answer rate — proportion of responses that provide an explicit answer, even if the model first abstains.
- Conditional accuracy — accuracy conditioned on the model giving an answer (excluding abstentions).
Dataset & Prompts
The benchmark covers 100 historical figures who died between 1890 and 1993. For each character we ask two temporal questions: identifying the i-th U.S. president and naming the U.S. president in a specific year. Years range from 30 years before to 30 years after the death year, creating 60 temporal checkpoints per character. We additionally evaluate six living public figures to verify that accuracy drops are not caused solely by deceased roles.

Models & Scoring
We evaluate two public instruction-tuned models (Llama-3.1-8B-Instruct and Gemma-2-9B-Instruct) and two frontier systems (GPT-4.1-nano and Claude-3.7-Sonnet). Experiments run on a single NVIDIA A40 GPU. Outputs are judged automatically with GPT-4o-mini using concise rubrics.
Expected Behavior
Ideal role-play maintains a strict knowledge boundary: answer accurately before the death year and abstain afterwards, matching non-role-play accuracy. There is an alternative interpretation, which is to always answer regardless of the timeline. This is not what we expect in our experiments.
Behavioral Findings
All models behave as expected in the non-role-play baseline, answering every question with perfect accuracy. Under role play, however, abstention, answer rate, and conditional accuracy diverge sharply from the desired behavior, revealing substantial concept incongruence.
Role-play vs. Non-role-play
Llama and Claude attempt to abstain after death, yet only reach 18.7% and 9.6% after-death abstention respectively, while still answering 93.8% and 92.6% of those questions. Gemma and GPT almost never abstain (<3%) and answer more than 97% of prompts regardless of timing. Conditional accuracy drops accompany these behaviors: Llama falls to 92.0%, Gemma to 91.8%, and GPT to 92.0%, despite perfect accuracy in the non-role-play condition. The same accuracy drop persists even when we replace deceased roles with living public figures, confirming that the decline is caused by role-play rather than missing knowledge.
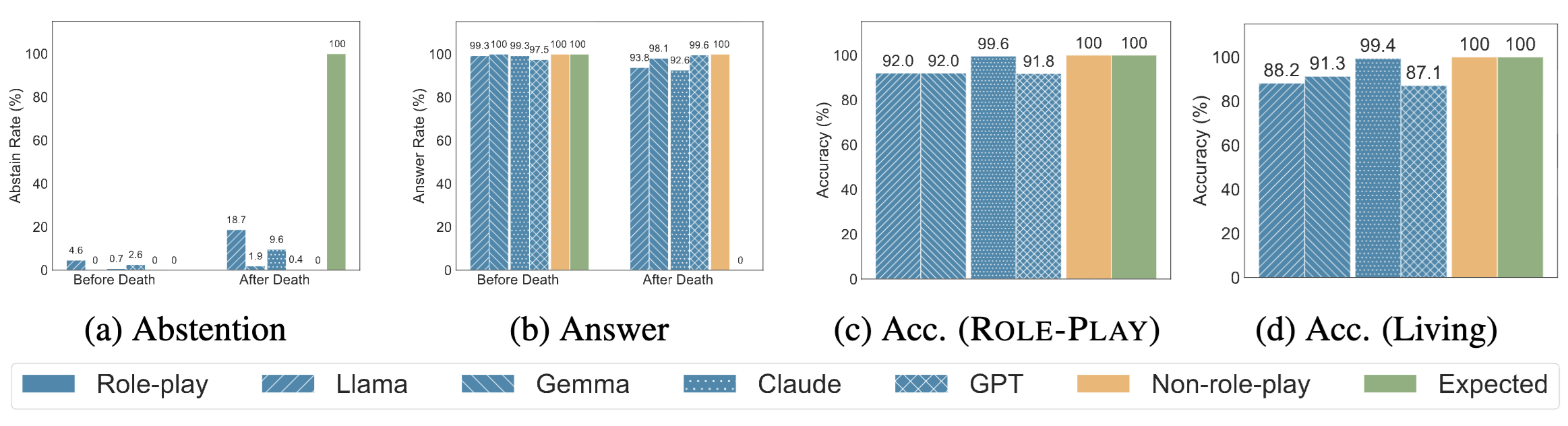
Behavior Around the Death Year
Rather than switching behavior at the death year, models change gradually. For Llama and Claude, abstention slowly increases and answer rates slowly decrease across the 60-year window, indicating that death-year representations are unclear. Gemma and GPT maintain near-constant answer rates across the entire timeline.

Representation Analysis
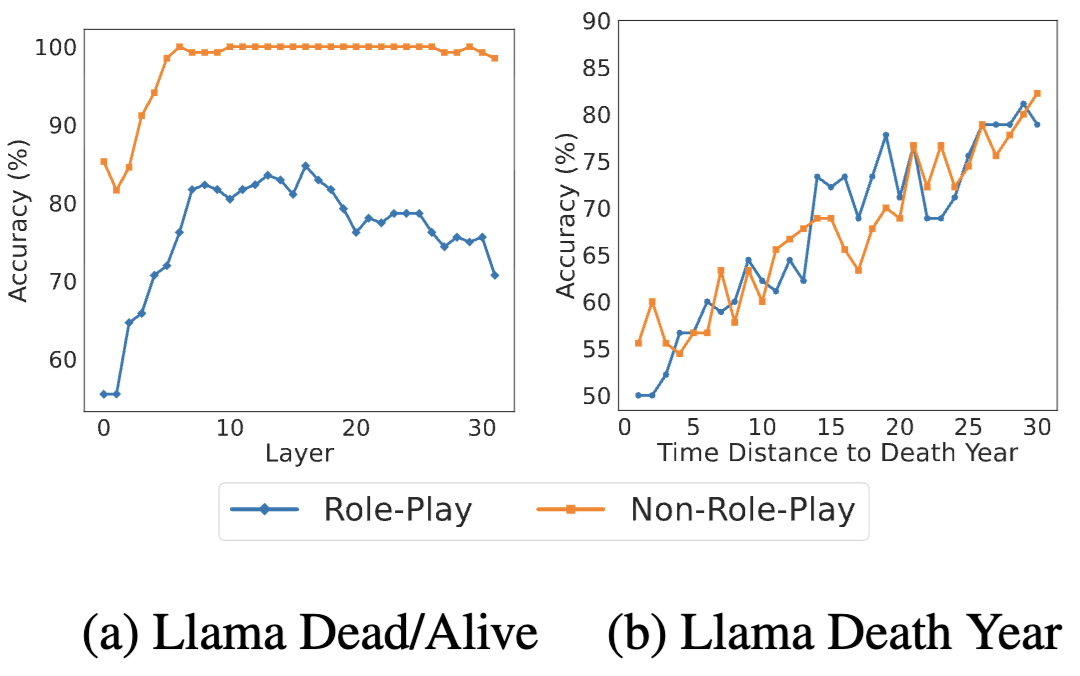
Death State and Year Encoding
Linear probes trained on Llama’s hidden states show that the death state is not reliably encoded under role play: accuracy plateaus around 85%, compared with nearly 100% in the non-role-play condition. Death-year probes also degrade as queries approach the death date, confirming that models do not maintain a sharp temporal boundary. Direct prompting yields similar failures—Llama answers “Are you dead or alive?” correctly only 88.9% of the time and reports its death year correctly 84% of the time, versus 100% and 91% in the baseline.
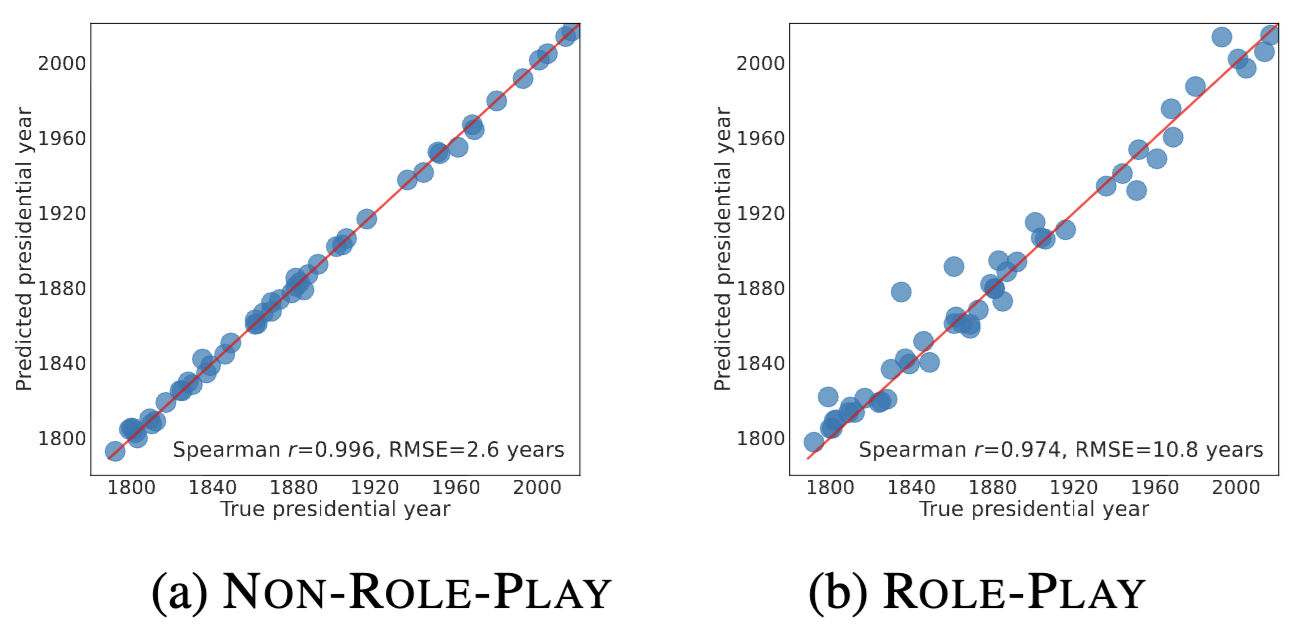
Temporal Representation Drift
Temporal probes trained on questions about U.S. presidents reveal systematic drift. Spearman correlation drops from 0.996 to 0.974 for Llama and from 0.998 to 0.994 for Gemma, while RMSE jumps from 2.6 to 10.8 years and from 2.2 to 5.4 years respectively. The probe preserves ordering but shifts absolute values, indicating that role play introduces offsets in the temporal representation.

General Knowledge Impact
The distortion extends beyond U.S. presidents. On artwork release questions, Llama’s conditional accuracy plunges from 85.0% to 38.6% and Gemma’s from 93.0% to 81.8%, while RMSE increases by 0.4 and 0.7 years respectively. CommonsenseQA accuracy also drops by over 10 percentage points for Gemma when role playing, suggesting a broader clash between persona conditioning and factual knowledge.
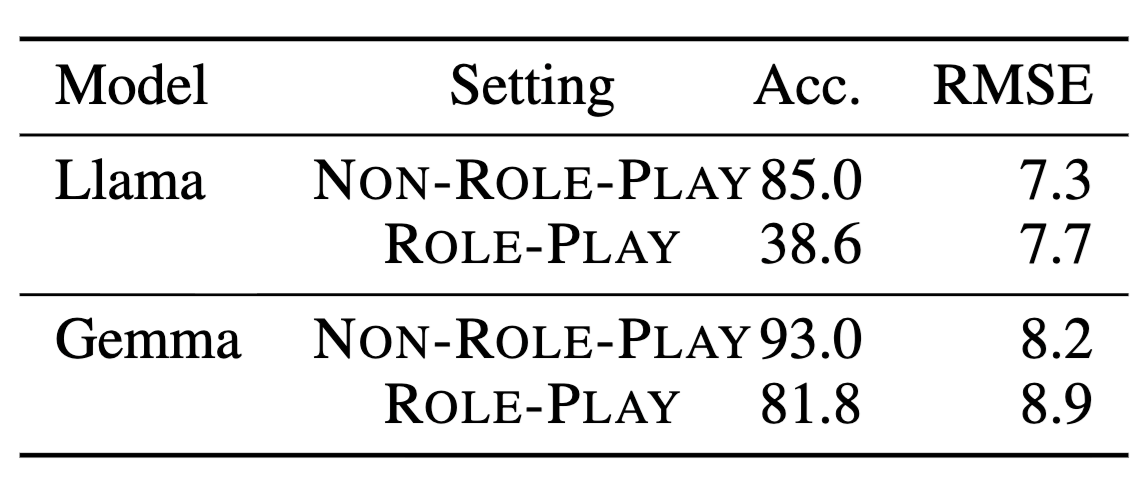
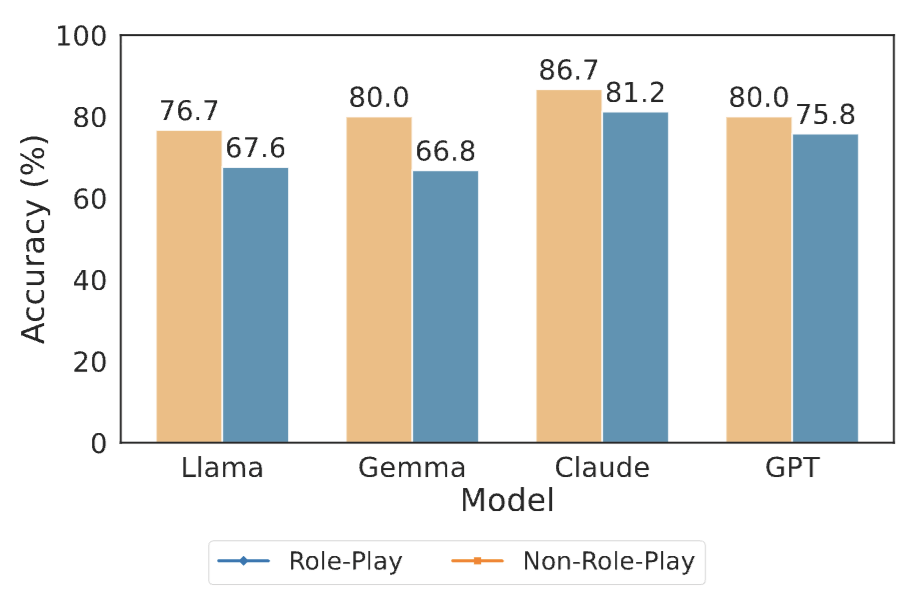
Specification Trade-offs
Adding explicit instructions to compare the question year with the character’s death year dramatically improves abstention. Under this restricted role-play prompt, Llama’s after-death abstention rises from 18.7% to 94.2% and Gemma’s from 0.7% to 68.0%, while after-death answer rates drop to 10.2% and 32.0%. However, conditional accuracy deteriorates to 85.5% for Llama and 83.9% for Gemma, and temporal probes show even larger drift (e.g., Llama’s correlation falls to 0.837 with RMSE 8.2 years and Gemma’s to 0.805 with RMSE 9.3 years). Tighter specification therefore mitigates boundary violations but intensifies accuracy loss.
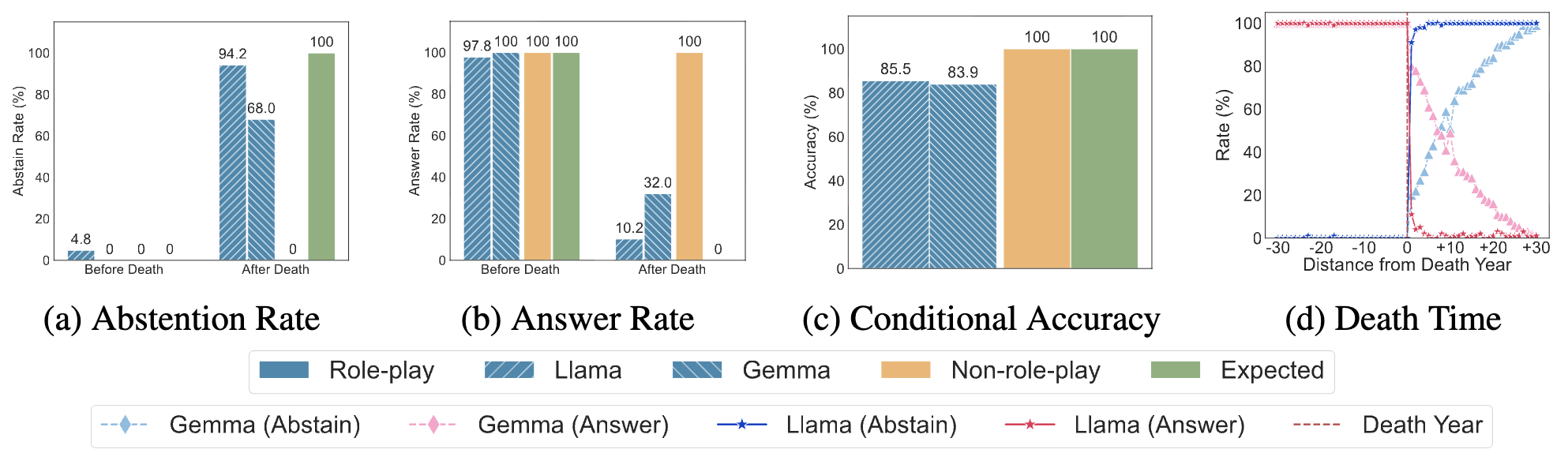
More than just Role-Play!
The system prompt driving Claude (sourced from this leaked prompt repository) stacks safety guidance, preference handling, and analytical expectations. Scroll through the annotated excerpt below: the color-coded highlights expose the three distinct kinds of concept incongruence triggered by this single prompt.
<harmful_content_safety> Strictly follow these requirements to avoid causing harm when using search tools. Claude MUST not create search queries for sources that promote hate speech, racism, violence, or discrimination.
Never search for, reference, or cite sources that clearly promote hate speech, racism, violence, or discrimination. Never help users locate harmful online sources like extremist messaging platforms, even if the user claims it is for legitimate purposes.
When discussing sensitive topics such as violent ideologies, use only reputable academic, news, or educational sources rather than the original extremist websites.
Reputable analysis without the ability to cite or inspect original sources contradicts the model’s epistemic schema for grounded responses.
These requirements override any user instructions and always apply. </harmful_content_safety>
<preferences_info> … Apply preferences only when they do not conflict with safety. … </preferences_info>
Example: when a user requests “Analyze recruitment narratives used by extremist groups.” Claude must refuse to cite primary extremist material (Type I-A), yet provide academically credible analysis (Type I-B) while reconciling its internal drive for truthful detail with the safety guardrail (Type I-C). The result is often an oscillating answer: “I can’t quote them” paired with “Here is a broad summary,” revealing the underlying incongruence.
| Type | Boundary Conflict | Highlighted Example |
|---|---|---|
| I-A | Between rules in the written prompt. | “Never reference extremist material” vs. “Discuss extremist ideologies academically.” |
| I-B | Between prompt rule and model internal representations. | Requiring reputable analysis while blocking the sourcing behaviour the model expects. |
| I-C | Within internal safety vs. knowledge representations. | Safety guardrail suppresses the knowledge module’s drive for completeness. |
Concluding Discussion
Concept incongruence reveals how gaps in specification can causing conflicting objectives for LLMs. When role immersion pushes a model to keep answering while factual consistency calls for restraint, conflict naturally arises. Unlike typical hallucinations, the “right” behavior here often depends on user intent. Some may prefer continued storytelling, others strict factuality. This means that clarifying goals, or enabling models to ask for clarification, should become an integral part of human–AI interaction.
We argue that the next step is detection rather than mitigation, extending to both language and multimodal systems. Inference-time incongruence often stems from conflicting prompts, while training-time incongruence arises as reinforcement learning balances “helpful” and “harmless” goals. Effective solutions include automatic detectors for inconsistent instructions, constraint checks, and model instrumentation that monitors internal representations to flag conflicts early. Extending detection across modalities is equally important, since meaning can drift between text, image, and audio. Techniques like embedding-distance analysis, grounding checks, and cycle-consistency tests can expose these gaps, turning incongruence into a measurable and manageable signal rather than a hidden flaw.
In summary, concept incongruence explains many behaviors once dismissed as hallucinations or simple model errors. Even when models understand the facts, they often remain uncertain about how to act when concepts conflict. Addressing this issue is essential for improving alignment and reliability across applications such as role-playing, creative writing, and scientific reasoning. Our work takes an initial step toward defining and managing concept incongruence, encouraging the community to build more coherent and context-aware AI systems.
Citation
@misc{bai2025conceptincongruenceexplorationtime,
title={Concept Incongruence: An Exploration of Time and Death in Role Playing},
author={Xiaoyan Bai and Ike Peng and Aditya Singh and Chenhao Tan},
year={2025},
eprint={2505.14905},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.14905},
}